How to Build an HTS Classification Agent

Introduction: Why Build an HTS Classification Agent?
HTS classification is a complex and tedious process with 18,000 codes that determine the duty on a product. Whether you’re an importer or a licensed customs broker, it's always valuable to have a second pair of eyes review your work.
A quick search reveals numerous online tools that use “AI” to provide you with HTS codes based on your product description. However, many businesses quickly discover that these generic solutions fall short. They are missing the unique context of your business's imports, and they frequently just output a single classification, when in reality there are usually several potential codes that could match to a given product description, especially when the product description lacks detail.
What if you could build an intelligent classification system tailored to your operations that outputs a range of potential codes based on your needs?
This article outlines how we did just that, delivering an HTS Classification Agent that is low-cost, fully customizable, and delivers classifications that (in my humble opinion) are damn good.
You can see our agent in action here:
Phase 1: Sourcing and Structuring the HTS Data
The bedrock of our agent is a dataset from the U.S. International Trade Commission (USITC) website (hts.usitc.gov).
1.1 Getting the Data from hts.usitc.gov
The hts.usitc.gov website provides an option to download the full classification schedule in structured JSON format.
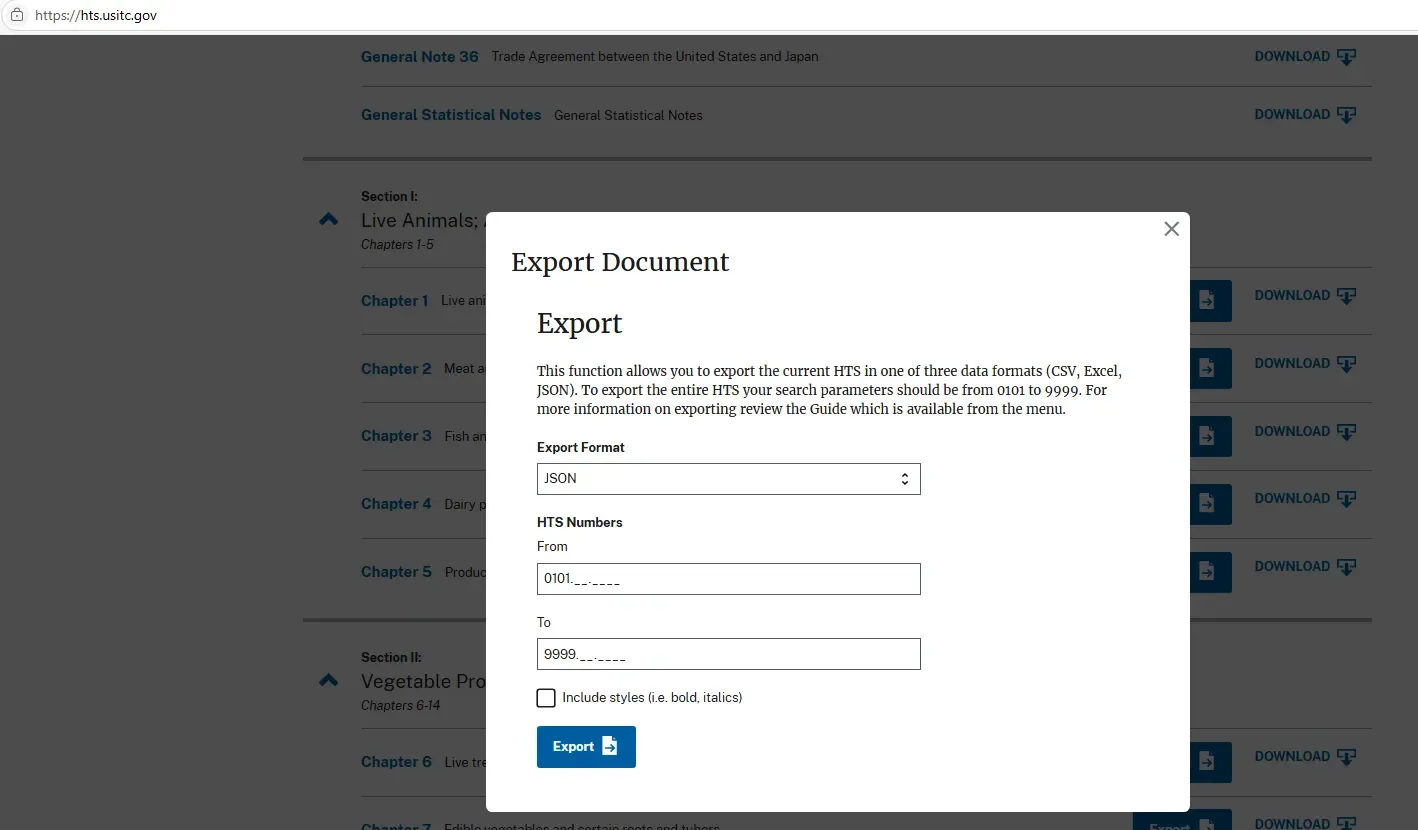
The website also provides a REST API, so instead of manual downloads, our system programmatically pulls this data to ensure that we always have the most current version.
Unfortunately, we found that one crucial piece of information—the high-level chapter headers—was not readily available. So, to obtain these chapter headers and their descriptions, we employed a web scraping tool - Firecrawl.
Here's the code snippet demonstrating how Firecrawl is used to scrape the HTS website for the chapter headers:
import re
from pathlib import Path
from firecrawl import FirecrawlApp
def get_hts_headers(app: FirecrawlApp, headers_save_path: Path = 'chapter_headers_final.txt', chapter_desc_save_path: Path = 'chapter_desc.json') -> list:
# Scrape the usitc website for HTS headers:
scrape_result = app.scrape_url('https://hts.usitc.gov/', params={'formats': ['markdown']})# clean and extract the headers from the markdown content
headers = scrape_result['markdown'].split('\n')
headers = [line.strip() for line in headers if line.strip()]
headers = [re.sub(r'\(.*?\)', '', header).strip() for header in headers]
headers = [i for i in headers if i not in ('Export','[Download]')]
start_index = headers.index('General Statistical Notes')
end_index = headers.index('- Section XXII:')
headers = headers[start_index+1:end_index]
chapter_descs = {}
for i, line in enumerate(headers):
line = line.strip()
if line.startswith('- ### [Chapter ') and line.endswith(']'):
# Extract the chapter number
chapter_number = line.split('[Chapter ')[1].split(']')[0]
if len(chapter_number) < 2:
chapter_number = '0' + chapter_number
# Get the description from the next line
if i + 1 < len(headers):
description = headers[i + 1].strip()
chapter_descs[chapter_number] = description
# save headers to a text file
with open(headers_save_path, 'w', encoding='utf-8') as file:
file.write('\n'.join(headers))
with open(chapter_desc_save_path, 'w', encoding='utf-8') as json_file:
json.dump(chapter_descs, json_file, ensure_ascii=False)
return headers, chapter_descs
With the chapter headers in-hand, we have a complete and up-to-date knowledge base.
1.2 Structuring the Data for AI Consumption
Once we have this raw data, the next step was to restructure it for LLM consumption. The raw JSON data, unaltered, is over 4 million tokens, so we aren’t just going to drop that into our prompt. Critically though, we also don’t just chunk it up and hope that the cosine similarity determined top K chunks will provide proper context.
Instead, we structure the data so that it's possible to pull specific, relevant parts that that still contain all the information needed for the agent to understand it within the broader context of the Harmonized Tariff Schedule. While we won't show all the intricacies, here's a breakdown of what we did:
- Initial Filtering: Filter out specific chapters (like 98 and 99) that contain special provisions not relevant for initial product classification.
- Description Enhancement: A key step involved propagating descriptions down the hierarchy. HTS codes often have a short description, but their meaning is fully understood only in the context of their parent headings. For example, a subheading "Other" might be preceded by its parent's description, like "Footwear with outer soles of rubber, plastics, leather or composition leather and uppers of leather".
- Duty Rate Propagation: Similarly, duty rates might not be explicitly listed at the lowest level. This happens when the rate is the same for all codes under a specific heading.
- Extraction of Key Levels: Finally, from our improved dataset, we extracted two key levels:
four_digit_codes: This list contains dictionaries, each with a 4-digit HTS code and its enriched description. This is perfect for an initial classification stage.final_full_codes: This list comprises dictionaries with the full 10-digit HTS codes, their complete enriched descriptions, and the associated duty rates. This granular data is used for the final selection stage.
Here is the original structure of the HTS data:
Chapter Header: Live Animals
[ {
"htsno" : "0101",
"indent" : "0",
"description" : "Live horses, asses, mules and hinnies:",
"superior" : null,
"units" : [ ],
"general" : "",
"special" : "",
"other" : "",
"footnotes" : [ ],
"quotaQuantity" : "",
"additionalDuties" : "",
"addiitionalDuties" : null
}, {
"htsno" : "",
"indent" : "1",
"description" : "Horses:",
"superior" : "true",
"units" : [ ],
"general" : "",
"special" : "",
"other" : "",
"footnotes" : null,
"quotaQuantity" : null,
"additionalDuties" : null,
"addiitionalDuties" : null
}, {
"htsno" : "0101.21.00",
"indent" : "2",
"description" : "Purebred breeding animals",
"superior" : null,
"units" : [ ],
"general" : "Free",
"special" : "",
"other" : "Free",
"footnotes" : [ {
"columns" : [ "general" ],
"value" : "See 9903.88.15. ",
"type" : "endnote"
} ],
"quotaQuantity" : null,
"additionalDuties" : null,
"addiitionalDuties" : null
}, {
"htsno" : "0101.21.00.10",
"indent" : "3",
"description" : "Males",
"superior" : null,
"units" : [ "No." ],
"general" : "",
"special" : "",
"other" : "",
"footnotes" : [ ],
"quotaQuantity" : null,
"additionalDuties" : null,
"addiitionalDuties" : null
}
...
The output of the data wrangling process, which feeds into our LLMs, would look something like this for the four_digit_codes:
[
{
"htsno": "0101",
"description": "Live animals
Live horses, asses, mules and hinnies."
},
]
...
And for the final_full_codes (representing the lowest-level codes with full details):
[
{
"htsno": "0101.21.00.10",
"description": "Live animals
Live horses, asses, mules and hinnies
Horses: Purebred breeding animals
Males",
"duty_rate": "Free"
},
]
...
We then use these structured datasets to feed specific, relevant info to our LLMs.
Phase 2: The Multi-Stage Classification Pipeline
The Harmonized Tariff Schedule is a decision tree. At the top we have chapters, and we branch down to the final 10-digit codes.
When classifying a product, we can generally eliminate the vast majority of code options by making decisions at the top of the tree (at the chapter, or 4-digit code level). We take advantage of this to reduce the size of data so that we don’t overwhelm our LLM with irrelevant information.
2.1 Orchestration with LangGraph
The overall workflow we developed looks like this:
#From classification_and_duties_deploy.py (conceptual snippet)
from langchain_core.messages import BaseMessage
from langgraph.graph import StateGraph, END
#Define the state of our graph
class AgentState(TypedDict):
product_description: str
chapters_list: list
four_digit_code_list: list
# ... other relevant state variables
#Build the graph
workflow = StateGraph(AgentState)
#Add nodes for each classification stage
workflow.add_node("chapter_selection", ChapterSelector().agent_node)
workflow.add_node("level_one_selection", LevelOneSelector().agent_node)
workflow.add_node("deep_selection", DeepSelector().agent_node)
workflow.add_node("final_selection", FinalSelector().agent_node)
#Define the edges (transitions between stages)
workflow.set_entry_point("chapter_selection")
workflow.add_edge("chapter_selection", "level_one_selection")
workflow.add_edge("level_one_selection", "deep_selection")
workflow.add_edge("deep_selection", "final_selectionn")
workflow.add_edge("final_selection", END)
app = workflow.compile()
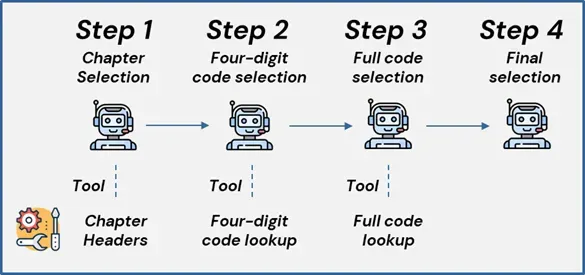
The journey looks like this:
Input: A user provides a product description, e.g., "Women's ankle socks, hot pink, size small; 45% polyester, 20% nylon, 25% cotton, 10% elastic."
- Chapter Selection: The
ChapterSelectorreceives this description, and selects relevant chapters. - Level-One Selection: The workflow transitions to the
LevelOneSelector. It pulls all the 4-digit codes for the chapters selected by the ChapterSelector, and selects relevant 4-digit codes. - Deep Selection: The
DeepSelectortakes over, diving into the next level of details. It pulls all the 10-digit codes for the selected 4-digit codes and determines which of the 10-digit codes are most relevant. - Final Selection: The
FinalSelectorreviews the chain of events and selects the final codes presented to the user.
2.2 Specialized Prompts and LLMs for Each Stage
Each node in our graph has a specific prompt. Let's look at ChapterSelector as an example:
self.system_prompt = """You are a helpful assistant that can answer questions about the Harmonized Tariff Schedule (HTS) of the United States.
The HTS is a system for classifying goods imported into the United States.
It is used by U.S. Customs and Border Protection (CBP) to determine the duties and taxes that apply to imported goods.
You will be provided with a product description, and you will need to help identify its relevant HTS code.
The first step will be to determine the correct chapters to search for the HTS code.
Here is a list of chapters and their descriptions:
{chapters_list}
Select the {n} most likely chapters, and be sure to provide your reasoning.
Consider what are the most likely chapters and make sure to select at least {n} options, since this is the first step we don't want our search to be too narrow."""
self.system_prompt = """You are a helpful assistant that can answer questions about the Harmonized Tariff Schedule (HTS) of the United States.
The HTS is a system for classifying goods imported into the United States.
It is used by U.S. Customs and Border Protection (CBP) to determine the duties and taxes that apply to imported goods.
You will be provided with a product description, and you will need to help identify its relevant HTS code.
The first step will be to determine the correct chapters to search for the HTS code.
Here is a list of chapters and their descriptions:
{chapters_list}
Select the {n} most likely chapters, and be sure to provide your reasoning.
Consider what are the most likely chapters and make sure to select at least {n} options, since this is the first step we don't want our search to be too narrow."""
self.human_prompt = """Based on the list of chapters provided, please select the {n} most likely chapters to consult for the HTS code for the following product: {product_description}."""
self.prompt = ChatPromptTemplate.from_messages(
[
("system", self.system_prompt),
("human", self.human_prompt),
]
)
Additionally, we found that in the initial nodes, faster models were delivering satisfactory results, while at the DeepSelector or FinalSelector nodes we preferred to go with “thinking” or “reasoning” models that use more inference-time compute for increased accuracy.
Phase 3: Beyond the Basics
The initial agent that we built for the demo above demonstrated strong performance, to the point that we felt it was producing better classifications than anything else we could find online. There were handful of additional features, however, that didn’t make it to implemention at that time, but that can further improve accuracy.
- Company specific context: Providing the LLMs with company-specific context is a significant opportunity. Since our initial agent was for a general demo, we didn't implement this. However, adding a description of the importer and its business is a quick and powerful improvement, and a more complex function to retrieve relevant information from the company's previous entries can drive even more accuracy.
- Simple Google search: Adding a simple Google search node can also be beneficial. I’ve certainly done this when researching HTS code myself, and it can unearth discussion forums and other online resources where people describe products and codes, potentially highlighting information that might otherwise be missed.
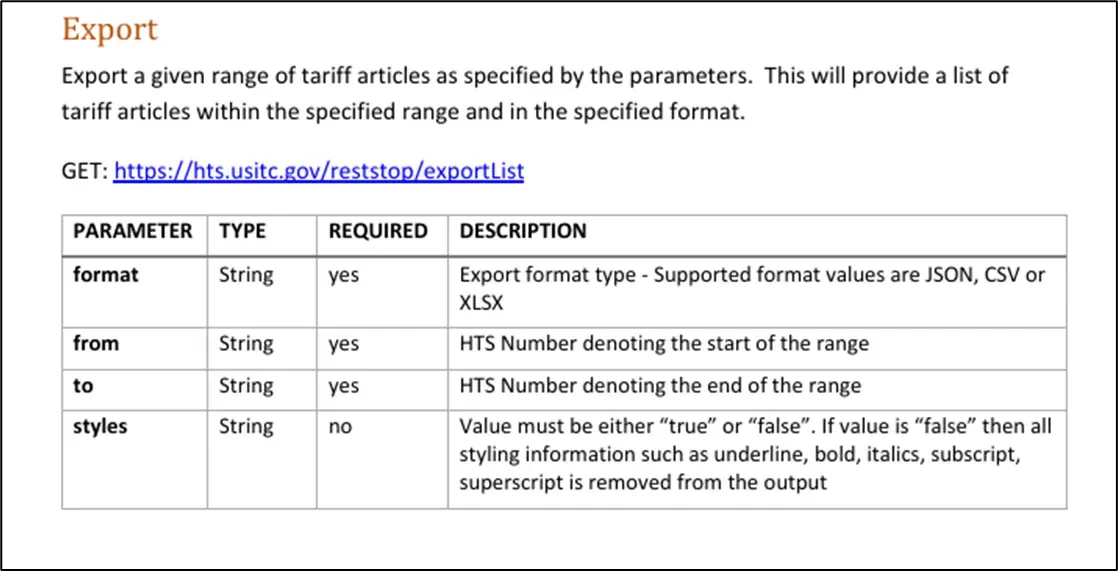
- CROSS ruling search: Finally, one of the biggest opportunities is creating a node to pull in information from the CBP Customs Rulings Online Search System, which provides rich additional context for our LLMs, including the thought process behind related classifications.
Next Steps
Whether you’re an importer, a customs broker, or a logistics service provider, an HTS classification agents present a low-barrier, high-value AI use case. If you are interested in deploying one for your business (or to offer to your customers), you can email jesse@severalmillers.com or book a meeting here to get started.
References
https://www.wsj.com/economy/trade/trump-tariffs-customs-brokers-c2091c77